Table of Contents
Automated Speech Recognition using Use of Class-Based Language Models to Transcribe Speech to Text
The Google n-gram viewer program from the top image shows that Pittsburgh (or Pittsburg) words can be spelled more than one way.) Using language models is one of the complexities behind spoken queries.
Related Content:
Understanding how Google handles vocal queries that are spoken goes to the heart of better understanding language models.
I have written about spoken queries in the post Google Speech Search Using Language Models
Many input approaches can be used with search engines. One that is becoming more common, or use with mobile devices, smart speakers, televisions, and desktops involves search by voice.
A new Google patent, granted March 23, 2021, focuses on speech recognition and calls it a “widely adopted and frequently used mode of interacting with computers.”
I have a speaker device and a phone that I can search with, and speech input is convenient and efficient; more than traditional input methods such as typing with a keyboard.
The patent points out that mobile computers often offer speech recognition services as an alternative input mode to typing characters through a virtual keyboard on a touchscreen.
Also, some computers accept voice commands from a searcher as a shortcut to performing certain actions on the computer.
We are told in the patent that “voice commands and other speech can be transcribed to text using language models that predict that certain sequences of terms occur in the speech.”
We also learn from the patent that “some language models group related terms into classes and can predict the likelihood that a class of terms occurs in a speech sample.”
So, this patent tells us about ways for dynamically adapting speech recognition for individual voice queries of a searcher using class-based language modeling.
So, a speech recognition system generates query-specific class models that each include a collection of related terms that the searcher is likely to say when he/she can be found in a particular context (such as seeking song titles when using a media player application).
This system also obtains a set of class-based language models.
This patent focuses on language modeling, and the post tells us that each class-based language model in the set can correspond to a particular class and can indicate probabilities of language sequences that include at least one term belonging to the particular class.
Also, each class-based language modeling used in the set may correspond to more than one candidate language class.
Language Models Using Rarely Occurring Terms
The speech recognition system then accesses generic language models using a residual unigram representing a residual set of terms in a language.
That residual unigram may be an unknown term unigram representing rarely occurring terms in a language or terms that are outside of the language model’s vocabulary.
The system then inserts respective class symbols associated with each class model at each instance of the residual unigram within a language model.
Thus, processed language modeling may include multiple class symbols at each instance of the residual unigram.
During the speech decoding process, for a particular candidate transcription that is determined to include a residual unigram, the system first identifies the appropriate class symbol to replace the instance of the residual unigram (e.g., based on respective probabilities specified by the class-based language models), and then selects a particular term from the collection of terms specified by the corresponding class model to insert into the position of the class symbol within the candidate transcription sequence.
The particular term can be selected by phonetically transcribing a corresponding portion of the searcher’s utterance, and identifying a term within the collection of terms specified by the class model that most resembles the phonetic transcription.
In this regard, the system is capable of dynamically inserting class terms from a set of query-specific class models to efficiently improve recognition capabilities when a searcher’s utterance includes strange or uncommon terms that are unlikely to be accurately recognized using basic speech recognition techniques.
Some approaches may include a method performed by one or more computers.
The method may include receiving a voice query from a searcher that includes:
(i) Audio data corresponding to an utterance of the searcher, and
(ii) Context data associated with at least the audio data or the searcher.
In response to receiving the voice query, one or more class models are then generated.
The one or more class models collectively identify
(i) The first set of terms based on the context data associated with the audio data or the searcher and
(ii) For each respective term in the first set of terms, a respective class to which the respective term is assigned.
At least some terms in the first set of terms are assigned to different ones of several classes.
A language model that includes a residual unigram representing a set of terms may then be accessed.
The language model may be processed for each respective class among the plurality of classes to insert, at each instance of the residual unigram that occurs within the language model, a respective class symbol associated with the respective class.
Transcription of the utterance of the searcher is then generated using the modified language model.
Features Of the Dynamic Class Language Model Approach
These and other approaches may include one or more of the following features.
Generating the transcription of the utterance of the searcher may include accessing one or more class-based language models that correspond to respective classes to which one or more terms within the first set of terms are assigned.
A respective probability that a term within the respective class occurs within a candidate language sequence at a position in the candidate language model sequence that corresponds to a position to a position of the respective class symbol for each respective class symbol that was inserted into the modified language model and based at least on probabilities indicated by a particular one of the class-based language models that corresponds to the respective class indicated by the respective class symbol is then determined.
The transcription of the utterance of the searcher using the determined probabilities is then generated.
One or more class models can include a single class model that identifies the first set of terms.
Also, each respective term in the first set of terms can be labeled with a respective class symbol that identifies the respective class to which the respective term is assigned, and the single class model can include terms assigned to the different ones of the plurality of classes.
Generating one or more class models can include generating multiple class models corresponding to different classes, and merging the multiple class models into a single class that includes terms assigned to different classes.
The residual unigram can represent infrequently occurring terms within a corpus of text samples in a language model.
The residual unigram can be associated with a residual class model that identifies the second set of terms. One or more class models can be generated by adding the first set of terms to the residual class model.
Processing the language model can be based on accessing the residual class model, and identifying the plurality of classes based at least on the first set of terms in the residual class model being assigned among the plurality of classes.
This language models patent can be found at:
Scalable dynamic class language modeling
Inventors: Justin Max Scheiner, and Petar Aleksic
Assignee: Google LLC
US Patent: 10,957,312
Granted: March 23, 2021
Filed: December 31, 2019
Abstract
This document generally describes systems and methods for dynamically adapting speech recognition for individual voice queries of a searcher using class-based language models.
The method may include receiving a voice query from a searcher that includes audio data corresponding to an utterance of the searcher, and context data associated with the searcher.
One or more class models are then generated that collectively identify the first set of terms determined based on the context data, and a respective class to which the respective term is assigned for each respective term in the first set of terms.
A language model that includes a residual unigram may then be accessed and processed for each respective class to insert a respective class symbol at each instance of the residual unigram that occurs within the language model.
Transcription of the utterance of the searcher is then generated using the modified language model.
How this Scalable Dynanmic Class Language Modeling Approach Works
This patent describes a way of dynamically adapting speech recognition for individual voice queries of a searcher using class-based language models.
It may address problems associated with automated speech recognition and automatically transcribing speech into text.
In response to receiving a voice query and associated context data, a speech recognition system may compile (e.g., on the fly) class models that specify a set of terms corresponding to a particular context that is potentially relevant to the voice query (such as searcher contacts, local restaurant names, applications previously used by the searcher).
Each class language model specifies a class designation with which the set of terms within the class model is assigned (e.g., song class, contacts class, etc.).
Each class model is also associated with a corresponding class-based language model that indicates probabilities of language sequences that include at least one term belonging to the particular class.
The speech recognition system utilizes the class models and the corresponding class-based language models to allow for more adaptable recognition capabilities when a searcher’s utterance includes strange or uncommon terms that are unlikely to accurately be recognized using basic speech recognition techniques.
The speech recognition system may incorporate residual unigrams (e.g., a unigram that represents unknown terms that are unlikely to be included in a language) within a generic language model, and then insert a predicted class term from a collection of terms of a class model at each instance of the residual unigram within the generic language model to increase the recognition accuracy of the strange or uncommon terms provided by the searcher.
Also, because each of the class models and corresponding class-based language models specifies terms and probabilities that are specific to the searcher’s activities (e.g., based on prior searcher data while in a particular context), the recognition capabilities using such techniques are capable of being adjusted on a query-by-query basis.
For context, language models are generally capable of determining likelihoods (e.g., probabilities) that a given sequence of terms would occur in a language.
N-gram models, for example, may indicate the probability of a particular term following a sequence of n-1 terms that precede the particular term. Thus, a 4-gram model may indicate the relative statistical likelihoods that the fourth term in the phrase, “The car is “, is either “red,” “blue,” “broken,” “big,” or another term.
For some approaches, the probabilities that a language model assigns to sequences of terms reflect statistical occurrences of the sequences in a set of data that was used to train the language model.
For example, the language model may be developed by examining a vast amount of language from sources such as webpages and other electronic documents, query logs, books, social media, etc.
The relative frequencies of sequences of terms in the source data may be determined and used as the basis for a language model.
One consideration that arises in creating language models, however, is that it is often difficult to train the model over a sufficiently large body of data to reliably estimate the likelihood of all permutations of the many terms that occur in a language. To this end, class-based language models can be employed, which leverage statistics among related terms in a language, thereby allowing the language model to predict the likelihood of sequences of terms, even for terms that do not often occur in the training data.
Class-based language models are generally language models programmed to determine likelihoods (e.g., probabilities) that a given sequence of terms and class symbols would occur in a language.
In some implementations, the class-based language model may be trained by replacing original terms in the training data, which belong to pre-defined classes of terms (e.g., topically related categories of terms), with corresponding class-based symbols. For example, consider the training sentence “Larry’s favorite pastime is watching Seinfeld re-runs and eating pizza.”
This sentence may be processed to replace its class-based terms with corresponding class symbols as follows: “#name favorite pastime is watching #tv_show re-runs and eating #food.”
The class-based terms that were removed from the sentence may then be added to a respective class model (e.g., “Larry” may be added to a #names class model, “Seinfeld” may be added to a #tv_show class model, and “pizza” may be added to a #food class model). The class models may each include a collection of terms belonging to the respective class for the model, and may also store data indicating the relative probabilities that each term in the class occurs in a language or a given utterance. The #tv_show class model, for example, may include a list of TV shows and may include respective probabilities that each show occurs in a given language sample.
At runtime, the class-based language model in a speech recognizer may then identify the classes for class-based terms in an utterance or other language sequence based on terms adjacent to or near the class-based term, and/or based on context data external to the language sequence.
Once the classes are identified, the language model may access the corresponding class models that indicate lists of terms for the identified classes, and one or more class-based terms selected from the class models for a transcription of an utterance.
For example, a class-based language model in a speech system that is decoding the utterance for “Larry’s favorite pastime is watching Seinfeld re-runs and eating pizza,” may determine that the utterance includes class-based terms from both the #tv_show class and the #food class based on the preceding terms “watching” and “eating,” respectively.
The language model’s #tv_show class may include a multitude of different television show titles, from which the term “Seinfeld” is selected (e.g., based on acoustical analysis of the utterance, and/or based on external context such as profile data for the speaker that indicates Seinfeld is a favorite show of the speaker). Similarly, the term pizza may be selected from the #food class.
In some cases, a speech system may dynamically generate class models that are customized to a specific speaker, the context of a specific utterance, or both.
These customized class models may facilitate accurate decoding of utterances that include class-based terms, including class-based terms that are overrepresented in the lexicon of a particular speaker as compared to the language generally.
For example, a general class-based language model that has been trained on a broad-base of training samples in a language may be much more likely to incorrectly transcribe the utterance “I invited Jacki to the house for dinner” as “I invited Jackie to the house for dinner” (misspelled name) because, although phonetically identical, the name “Jackie” is more common as an English name than is the name “Jacki.”
However, some speakers are much more likely to refer to “Jacki” without an -e than would the general population, such as speakers who are friends, family, or colleagues with a “Jacki,” or who otherwise communicate frequently with a “Jacki.” Therefore, before determining a transcription for the utterance, the speech system may dynamically generate a speaker- (searcher-) specific class model that skews the likelihood of an utterance from the speaker including the name “Jacki” higher than the likelihood for “Jackie.”
The class-based language model may be generated by augmenting lists of class-based terms in a general class-based language model with class-based terms that are determined to be relevant to a context of an utterance that is to be decoded, such as information about the speaker of the utterance.
The classes in a class-based language model may include only class-based terms that are determined to relevant to a context of the utterance (e.g., searcher-specific or utterance-specific terms), or they may include a mix of generally determined and searcher-specific or utterance-specific terms.
Terms that were not included in the classes of a static or general language model may be added to the classes of a custom, dynamically generated language model. The probabilities associated with terms in a general language model may be adjusted in the custom, dynamically generated language model.
For example, upon receiving a request to transcribe an utterance spoken by Bill, a speech recognition system may obtain (e.g., from a local or remote context server) context data associated with Bill and/or the specific utterance that is to be transcribed.
The context data may include, for example, an indication of the location that the utterance was spoken, a list of names in Bill’s contact list, a list of names of searchers to whom Bill is connected on social media, or a combination of these and more. The context data may show that one of Bill’s closest contacts is Jacki.
Accordingly, the speech system may dynamically generate a customized #names class model for transcribing Bill’s utterance, which may be incorporated into a dynamic, searcher-specific class-based language model.
The customized language model may add all or some of Bill’s contacts to the #names class, and/or may re-calculate the probability distribution among the terms in the #names class.
For example, the term “Jacki” may be assigned a higher probability, whereas the term “Jackie” may be removed from the class or assigned a lower probability.
A speech system may automatically and dynamically generate a customized class-based language model for every request that it receives to transcribe an utterance.
For example, if the speaker system were implemented as a cloud-based service for transcribing utterances from a wide range of searchers, the speech system may dynamically generate a custom class-based language model for the specific searcher who submitted a request to transcribe an utterance (under the assumption that the searcher is the speaker, for example).
Before the speech system has transcribed the utterance, however, the speech system may be unaware of which classes, if any, are implicated in the utterance for any given request.
Accordingly, the speech system may generate, on the fly, dynamic class models for all the classes for which context data is available.
For example, upon receiving a request to transcribe an utterance from the searcher Bill, the speech system may dynamically generate a class-based language model that includes a range of customized classes.
After the custom classes and language model are built, the speech system may then use the custom language model to decode the utterance and to determine a transcription for the utterance.
A speech recognition system that has adaptive query-specific recognition capabilities for transcribing an utterance of a searcher
The system includes a search device that receives audio data encoding an utterance of a voice query submitted by the searcher.
The searcher device also obtains and/or stores context data associated with the searcher (e.g., historical activity data), or associated with the voice query (e.g., reference to information included within the query, present searcher location, etc.).
The example shown may illustrate how the system may be used to generate a transcription for a voice query that includes unusual or uncommon words that are likely to be detected as unknown words by traditional speech recognition systems. For instance, such speech recognition systems may incorrectly transcribe the terms “LABY GAMA” and “OGCAR” as “LADY GAGA” and “OSCAR,” respectively, because the latter terms are significantly more likely to occur within a language specified by a generic language model.
However, the system, with its use of class models and class-based language models, may instead use techniques described below to correctly transcribe the unusual or uncommon terms included within voice query.
The system also includes a server with an associated database that stores class models and corresponding class-based language models, and a residual unigram model.
The server includes software modules such as a language model processor and a transcription module that execute processes related to speech recognition as described more particularly below.
Referring to the example shown, the searcher initially submits the voice query with an instruction to place a song sent from a contact (e.g., “PLAY LABY GAMA SONG SENT FROM OGCAR”).
The voice query is encoded as the audio data and transmitted, along with the context data, from the searcher device to the server.
The server then initiates a speech recognition process, including generating and using the dynamic class models to insert class terms within a candidate transcription sequence.
The output of the speech recognition process is the transcription, which is then provided back to the searcher device for output in response to the received voice query.
The system initially detects an utterance of the voice query at the searcher device.
The searcher device may generally be any type of electronic computer that is capable of detecting and recording audio data, and facilitating the processing of the audio data locally on the searcher device, or at the server, or both.
For example, the searcher device may be a smartphone, a tablet computer, a notebook computer, a personal desktop computer, a smartwatch or any other type of wearable computer, or any other type of electronic device.
The searcher device may include a speech recognition service that runs within an operating system or an application executed on the searcher device.
The speech recognition service may convert speech to text or may perform certain actions on the searcher device in response to receiving voice commands from the searcher.
The searcher device may further include a microphone that detects an audio signal when the searcher speaks an utterance and an analog-to-digital (A/D) converter that digitizes the audio signal. The searcher device may also include a networking interface for communicating with other computers over wired and wireless networks, an electronic display, and other searcher input mechanisms, some of which are described concerning FIG. 6 below.
Upon detecting the utterance of the voice query, the searcher device provides audio data of the utterance to a speech pre-processor that may be located on the searcher device, the server, or both.
The speech pre-processor may generally serve as the first stage of a speech recognizer that is configured to transcribe the utterance to text.
The speech pre-processor can generate processed speech data that is capable of recognition by the decoder and its associated language models.
The pre-processor may include an acoustic model that determines phenomes or other linguistic units of the utterance from the audio data.
The acoustic model may determine the most likely set of candidate phonemes or linguistic units that are spoken in short time intervals of the utterance of the voice query.
This data can then be used by the decoder to transcribe the utterance. The decoder can include, or operate in conjunction with, language models that generally operate at a higher semantic level than the acoustic model.
For example, whereas the acoustic model may map very short segments of the audio signal to short linguistic units (e.g., phonemes) with little, if any, concern for how the linguistic units to piece together to form a coherent transcription, the language models may make sense of the collection of linguistic units to determine a transcription result that reflects actual sequences of terms that are likely to occur in a language.
The speech recognizer of the system may be implemented locally on the searcher device, or remotely from the searcher device (e.g., on the server).
Different components of the recognizer may be implemented locally, while others are implemented remotely.
In implementations where the speech recognizer is implemented remotely, the searcher device may transmit the audio data to a server that implements the speech recognizer on one or more computers separate and apart from the searcher device.
For example, the searcher device may send the audio data (e.g., in a compressed and encrypted format) to the server over the Internet.
The server may then handle the received audio data by providing it to the speech pre-processor and the decoder, and then performing the recognition processes as described below.
Upon receiving the context data (and optionally the audio data), the server generates a set of class models that each includes a collection of terms that belong to a particular class for the respective class model (e.g., SONG and CONTACT class models as depicted in FIG. 1).
The class models are compiled by the server after each submitted voice query so that the collection of terms accurately reflects up-to-date information at the time of query submission.
As an example, if the searcher adds a new contact to his/her contact list after the most recently submitted voice query, but before the submission of the voice query, the class model 130a is compiled after receiving the audio data so that the newly added contact is included within the class model.
In this regard, stored class models within the database can be adjusted by the server on a query-by-query basis to more accurately reflect changes in class-related information (e.g., contact list).
In addition to adjusting pre-existing stored class models, the server is also capable of generating new class models in response to receiving a voice query (e.g., in response to receiving context data associated with a voice query).
For example, the server may generate a new class model if the received context data indicates that the searcher has recently performed a particular action that is associated with a new group of terms (e.g., performing actions related to a new location that the searcher has entered into).
In other examples, the server may also be capable of generating new temporary class models that are associated with a searcher for a predetermined time when a searcher is in a particular context (e.g., during a trip when the searcher is temporarily in a particular location).
In these examples, the server may be capable of identifying the applicable class models to use within the recognition process based on the context information included with context data.
Although FIG. 1 depicts two examples of class models being compiled by the server in response to receiving the voice query, in other implementations, the server is capable of compiling a greater number of class models based on the information associated with the voice query or the context data.
For example, the server may compile a large number of class models to increase the probability of generating an accurate transcription if the context data indicate large variations in searcher behavior and/or if the voice query includes a large number of strange or unknown words.
The server may also obtain a set of class-based language models that correspond to the compiled class models, respectively.
The system may have generated and stored the class-based language models before receiving the voice query including audio data and context data.
The language models may be a set of class-based language models that are trained on language sequences that include class symbols in place of class-based terms that initially occurred in the language sequence.
For example, a first class-based language model corresponding to the class of the song may be generated by identifying a set of text samples (i.e., language sequences) that all include song names (i.e., particular class terms), pre-processing the text samples to replace the song names in the text samples with a class symbol (e.g., #SONGS), and then training the language model using the pre-processed text samples so that the language model identifies probabilities that different combinations of terms in a language would include a song name as indicated by the #SONGS class symbol.
A similar process may be employed to generate a second class-based language model corresponding to the contacts class, although with processed text samples that each includes a #CONTACTS class symbol.
For instance, in the example depicted in FIG. 1, the language model 132a specifies a higher probability of “0.63,” compared to the language model specifying a lower probability of “0.31” for a class term occurring after “SENT FROM” within a candidate transcription sequence.
This indicates that a CONTACT class term is more likely to occur after the terms “SENT FROM” within a candidate transcription sequence.
The class-based language models may be trained specifically for a particular searcher based on training the language models with training data that includes prior sentences or examples submitted by the searcher that include class terms. As described herein concerning other processes, the training procedures for the class-based language models may be iteratively performed between successive query submissions to adjust indicated respective probabilities based on reoccurring searcher behaviors and/or updated context data obtained by the searcher device.
As the server compiles the class models, the server also obtains a residual unigram model and incorporates the obtained model into the initial language model. Generally speaking, the residual unigram model can identify list terms that are likely to be problematic for recognition due to any of a variety of reasons.
For instance, the residual unigram model may include a collection of terms that have been previously incorrectly transcribed by the speech recognizer of the system, that is unlikely to be included within the language specified by a language model of the speech recognizer, or that are out-of-vocabulary (OOV) of the searcher.
In other instances, the residual unigram model may include terms included in queries where the searcher has subsequently transmitted a repeat query, indicating that the included terms were incorrectly recognized by the speech recognizer.
The residual unigram model may also be dynamically adjusted between successive query submissions by the searcher to adjust the collection of residual unigrams based on the recognition performance of the speech recognizer.
After compiling the class models, and obtaining the residual unigram model, the server may then generate a union model by joining the class models and the residual unigram model.
The union model includes each of the respective class terms specified by the class models and the terms specified by the residual unigram model.
The terms that are joined from class models into the union model may be labeled to indicate the class with which they are associated.
For example, a first-term that occurs in the union model that was taken from a #songs class model may be expressed in the union model as ‘SONG_NAME’, whereas a second term that occurs in the union model that was taken from a #contacts class model may be expressed in the union model as ‘CONTACT_NAME.’
Referring now to the language model processor, the initial language model is processed offline before the start of the speech recognition process performed by the system.
The initial language model may be a generic language model that specifies a set of respective probabilities for a collection of terms that indicate likelihoods that respective terms occur within a language associated with the language model.
Before receiving the voice query, the language model processor processes the initial language model and generates the processed language model.
The language model processor may generate the modified language model using a variety of techniques.
The language model processor incorporates residual unigrams into the initial language model as a pre-training feature.
In such implementations, the initial language model is trained on data in which terms belonging to a particular class are replaced with a residual unigram symbol (e.g., “#UNK”).
At runtime, the initial language model then scores the likelihood that the class term at any given position within a transcription sequence is a term included within the residual unigram model.
The language model processor incorporates the residual unigram symbol as a post-training procedure.
As one example, after the initial language model is trained, the language model processor can initially insert a symbol associated with a residual unigram (e.g., “#UNK”) at each instance of a term that is also included within a collection of terms specified by the obtained residual unigram model.
The residual unigram may be provided to indicate the likelihood that other terms within the vocabulary of the language model represent incorrect transcriptions of an utterance.
The language model processor can insert class symbols associated with each of the class models at each instance of the residual unigrams within the language model to generate a modified language model. In the example depicted, the terms “LABY GAMA” and “ONDOGULA” within the initial language module are initially identified as residual unigrams, and then instances of these terms in the initial language model are then replaced with two class symbols (e.g., “#SONG,” “#CONTACT”) corresponding to the SONG and CONTACT classes of the class models.
The transcription module uses the modified language model to generate the transcription for the voice query.
For instance, the transcription module may initially insert class symbols associated with the class models into each instance of the residual unigram within the processed language model to generate the processed language model. In the example depicted in FIG. 1, the transcription module replaces two instances of the residual unigram symbol with two corresponding class symbols associated with the class models.
The inserted class symbols represent alternative transcription pathways for inserting class terms within a word lattice for a candidate transcription sequence.
The transcription module then generates a candidate transcription sequence for the voice query (e.g., “PLAY #SONG SENT FROM #CONTACT”).
In generating the candidate transcription sequence, the transcription module initially identifies locations within the sequence where a residual unigram symbol may be included (e.g., PLAY #UNK SONG SENT FROM #UNK) using the processed language model.
The transcription module then selects, for each instance of the residual unigram symbol, the appropriate class symbol to replace the residual unigram symbol.
For instance, the transcription module identifies the appropriate class model based on the respective probabilities indicated by the class-based language models.
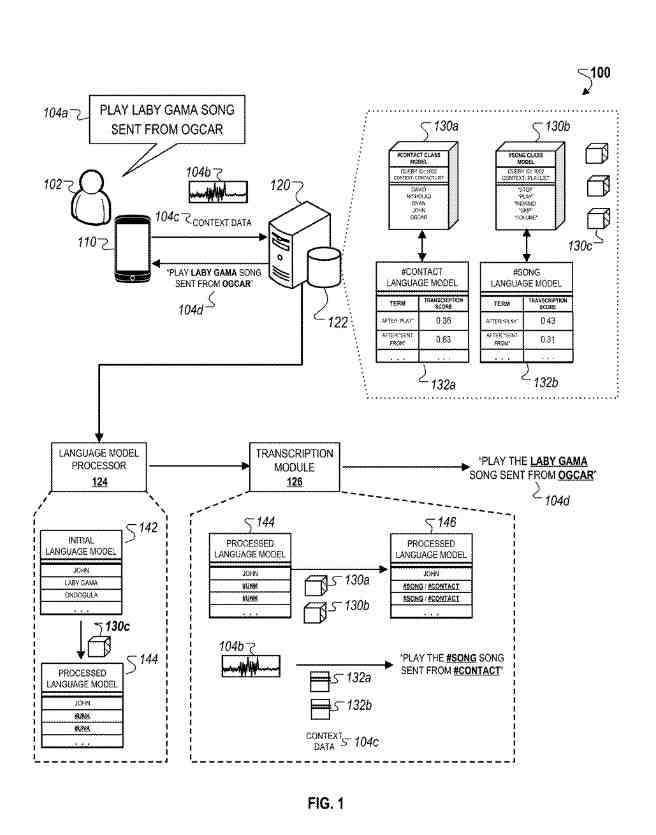
In the example depicted in FIG. 1, the transcription module selects the #SONG symbol to replace the first instance of the residual unigram symbol within the candidate transcription sequence based on the language model specifying a higher probability for a SONG term occurring after “PLAY” than the probability specified by the language model 132a for a CONTACT term.
Likewise, the transcription module selects the #CONTACT symbol to replace the second instance of the residual unigram symbol within the candidate transcription sequence based on the language model 132a specifying a higher probability for a CONTACT term occurring after “SENT FROM” than the probability specified by the language model for a SONG term.
After inserting the appropriate class symbols for instances of the residual n-grams within a candidate transcription sequence, the transcription module then selects the most probable class term to insert for the corresponding class symbol.
The most appropriate term is selected based on comparing each of the terms within the class model to a phonetic transcription of a corresponding portion of the utterance of the voice query.
For example, the transcription module inserts the class term “LADY GAMA” from the SONG class to replace the corresponding class symbol within the candidate transcription sequence because this term most closely resembles the utterance “LE-DI GA-MA” indicated by the audio data encoding the utterance of the searcher.
Likewise, the transcription module selects the class term “OGCAR” from the CONTACT class to replace the corresponding class term within the candidate transcription sequence because this term most closely resembles the utterance “OG-CA-AR” indicated by the audio data.
In the example depicted in FIG. 1, although the terms “LABY GAMA” and “OGCAR” are identified as residual n-grams, they are nonetheless included in the generated transcription because the class-based language models indicate high probabilities for these terms when the searcher is in the context associated with the class models (e.g., CONTACT LIST and PLAYLIST).
In this regard, the interpolated language model indicates a higher probability for “LABY GAMA” than for “LADY GAGA” which is the closest term that a generic speech recognizer is likely to predict based on the increased likelihood for a query to include “LADY GAGA” over “LABY GAMA.”
The transcription module then uses the interpolated language model to insert the term “LABY GAMA” for the “#SONG” class symbol and the term “OGCAR” for the “#CONTACT” class symbol, resulting in the generated transcription.
A graphical representation of combining class-based models with a residual unigram model to generate a union model
As discussed herein concerning language model processing image, the class-based models specify a collection of terms that are each assigned to a particular class (e.g., SONG class, and CONTACT class), whereas the residual unigram model specifies a collection of terms that can be, for example, unknown words that are unlikely to occur within a language spoken by the searcher, out-of-vocabulary terms for the searcher, or other terms that can potentially cause recognition inaccuracies.
The server joins the class models and the residual unigram model into a single union model to improve the processing of the initial language model. For instance, the generation of the union model allows the language model processor to process the initial language model using a single model as opposed to successive processing using various individual class models.
As depicted, the union model includes each of the collection of terms for each class model as well as a class identifier corresponding to a respective class symbol associated with each class.
FIGS. 3A-3C depicts graphical representations of word lattices generated by a language model for transcribing an utterance of the searcher.
The lattices generally indicate possible transitions of terms, n-grams, and/or class symbols in language sequences that represent candidate transcriptions of a voice query.
The lattices may also assign scores to each of the transitions that indicate a likelihood that the transition would occur in the language sequence.
For example, FIG. 3A shows that the initial term in the voice query may be either ‘Play’ or ‘Pray’, as indicated by the transitions from nodes.
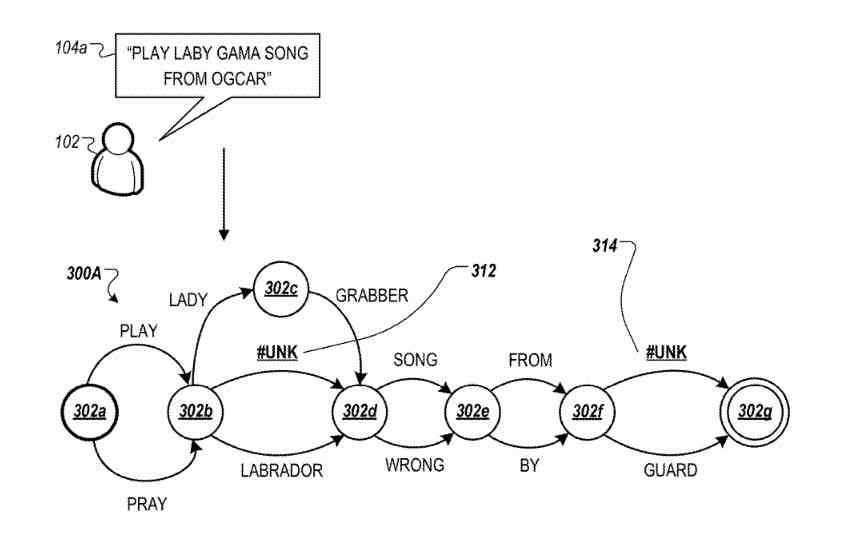
Although not shown, each transition may be scored. For example, lattice may indicate a 70-percent likelihood that the first term is ‘Play’ and only a thirty-percent likelihood that the first term is ‘Pray.’ Given the preceding term as being either ‘Play’ or ‘Pray,’ the lattice then indicates respective probabilities that the second term in the voice query is any of the outbound transitions from a node (e.g., ‘Lady,’ #unk, or ‘Labrador’).
A speech decoder may select the path through a lattice that has the highest score as indicated by the transitions as the most likely transcription of a voice query.
An initial word lattice that the language model has generated and that includes a residual unigram, represented by the #unk unknown terms symbol.
FIG. 3B illustrates an intermediate word lattice in which respective class symbols associated with different class models are inserted into the word lattice from FIG. 3A at each instance of the unknown symbol.
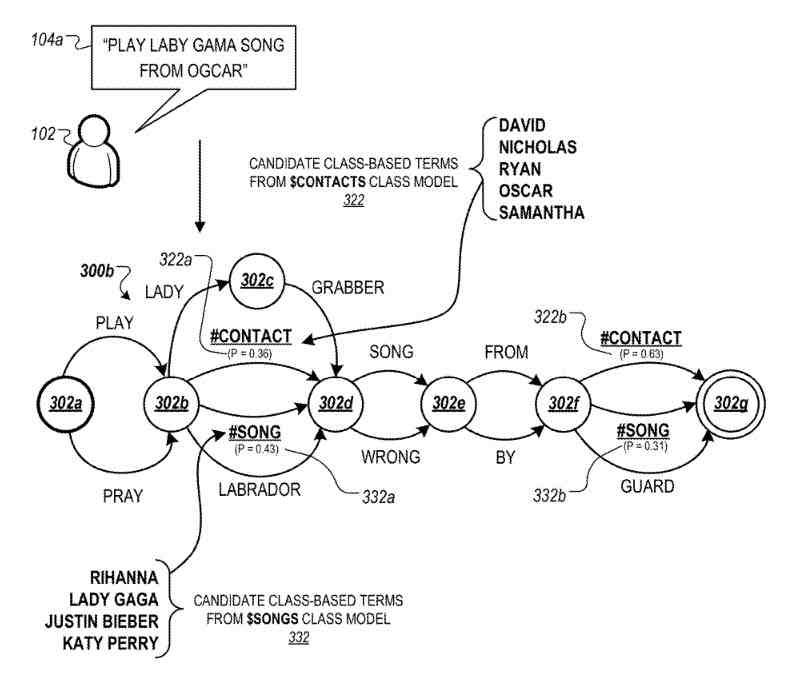
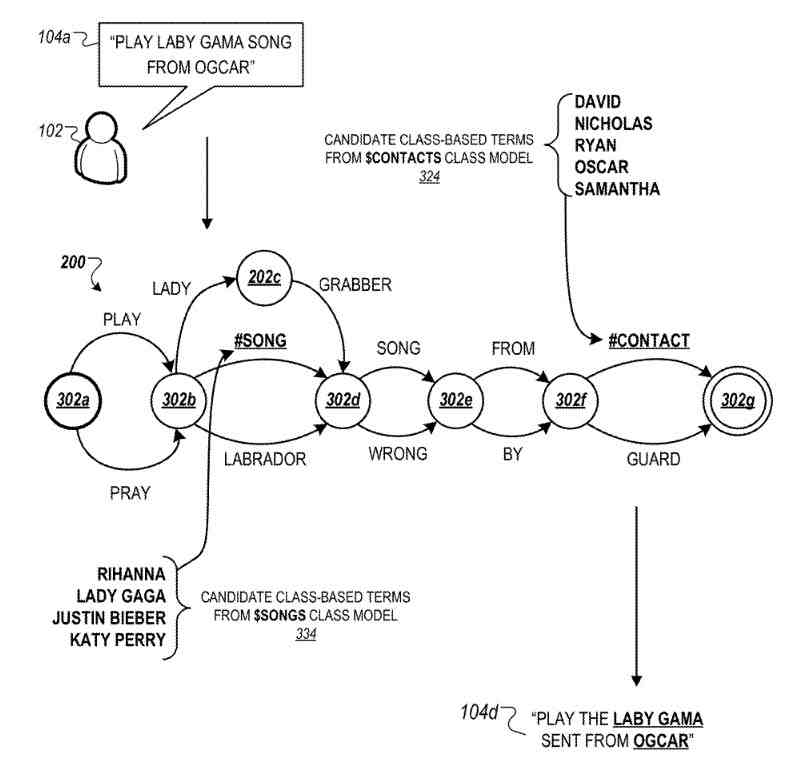
FIG. 3C illustrates an augmented word lattice in which the most probable classes are selected and individual terms from the classes are spliced into the word lattice from FIG. 3B.
In general, the system initially identifies a set of residual unigrams for a particular candidate transcription sequence (e.g., “LABY GAMA” and “OGCAR” in FIG. 1).
The system then inserts an unknown symbol into each instance of the identified residual unigrams.
During a recognition process, the system then inserts a class symbol corresponding to the class model that is determined to be the most appropriate for each instance of the residual unigrams into the corresponding position of the residual unigrams within the candidate transcription sequence.
Finally, the system then inserts the most probable term from among the collection of terms of the appropriate class models into each instance of the class symbols.
Referring initially to FIG. 3A, the word lattice is shown for transcribing an utterance for the voice query of the searcher.
The word lattice is represented as a finite state transducer that includes one or more nodes that correspond to possible boundaries between words.
The word lattice includes multiple pathways for possible words in the candidate transcriptions of the utterance represented by the word lattice.
Also, each of the pathways can have one or more weights or possibilities of a particular edge being the correct edge from the corresponding node.
The weights can be determined by a language model and can be based on, for example, confidence in the match between the acoustics for a corresponding portion of the utterance audio signal and the word for that edge and how well the word fits grammatically and/or lexically with other words in the word lattice.
In a word lattice determined by an n-gram language model, for example, the probability of a given word may be based on a statistical likelihood that the word would follow the immediately preceding n-1 words.
In the example depicted in FIG. 3A, the system identifies probable paths that include possible instances of residual unigrams between nodes, and between instances 302f and 302g. The system then generates alternative paths that include the residual unigram symbols 312 and 314.
Referring now to FIG. 3B, the intermediate word lattice provides alternative paths the class models at each instance of the residual unigram symbols in the word lattice.
As depicted, the word lattice includes two alternative class-based pathways between node–one with a “#CONTACT” class symbol where candidate class-based terms from the class model 130a may be inserted, and another with a “#SONG” class symbol where candidate class-based terms from the class model may be inserted.
The word lattice also includes two alternative class-based pathways between nodes for the same class models.
In these two examples, the system generates alternative pathways for all compiled class models at each instance of the residual unigram symbol within the word lattice.
For example, although FIG. 3B depicts two-class models, if the system had compiled five class models, then at each instance of the residual unigram symbol between nodes, the lattice would include five alternative pathways representing alternative pathways for class-based terms from each of the five compiled class models.
The system may identify the set of class symbols to insert at each instance of the residual unigram symbol by accessing the union model that identifies labeled terms from multiple class models.
Based on the labels that indicate classes associated with respective terms in the union model, the system can insert into the lattice class symbols for all or some of the classes that are represented by terms in the union model.
Each alternative class-based pathway is also associated with a probability that indicates the likelihood that a class-based term is a correct term to include between two particular nodes within a transcription of the utterance of the voice query.
The respective class-based pathway probabilities may work with, for example, the terms predicted for preceding or subsequent pathways within a transcription sequence, the present context associated with the searcher, the context associated with the received voice query, among other types of linguistic indicators.
In some instances, certain terms within a candidate sequence work with particular class models.
For example, the presence of voice commands such as “PLAY” or “REWIND” within a candidate transcription associated with the SONG class, whereas other phrases such as “SENT FROM” or “EMAIL TO” may be associated with the CONTACT class.
In the example depicted, the class-based pathway between nodes for the “#CONTACT” symbol associated with a probability of “0.36,” whereas the alternative class-based pathway for the “#SONG” class symbol is associated with a probability of “0.43.”
This indicates that there is a higher likelihood that a term from the SONG class included in this position within the correct transcription sequence of the voice query.
In contrast, the class-based pathway between nodes for the “#CONTACT” class symbol has a probability of “0.31,” whereas the alternative class-based pathway for the #”SONG” class symbol is associated with a probability of “0.63,” indicating that there is a higher likelihood that a term from the CONTACT class is in this position within the correct transcription sequence of the voice query.
Referring now to FIG. 3C, the word lattice works with the most probable class selected for each instance of the residual unigrams between nodes, and nodes. In the example, the SONG class is from the first class-based pathway between nodes, and the CONTACT classgoes with for the second class-based pathway between nodes.
The system selects the most probable term within the collection of terms associated with each class to insert into each instance of the class symbol within the candidate transcription sequence.
In some instances, the class term is identified and the transcription module selects the SONG term “LABY GAMA” to insert into the candidate transcription sequence because this term most closely resembles the utterance “LE-DI-GA-MA” indicated by the audio data.
Instead of selecting a class term to insert at each instance of a class symbol from the corresponding class models, the system may instead select the class terms from a combined model such as the union model as depicted in FIG. 2.
In such implementations, the system may match the class identifier within the union model against each instance of a class symbol to filter and select the most probable term to insert into the locations of the transcription sequence.
An exemplary process for dynamically adapting speech recognition for individual voice queries of a searcher using class-based language models
Briefly, the process may include receiving a voice query, generating one or more class models associated with respective classes, accessing a language model, processing the language model for each respective class, and generating a transcription.
In more detail, the process may include receiving a voice query.
For instance, the server may receive the voice query from the searcher. The voice query may include the audio data corresponding to an utterance of the searcher and context data associated with either the audio data or the searcher.
For example, as depicted in FIG. 1, the context data can be a list of contacts stored on the searcher device or metadata associated with songs previously played by the searcher (e.g., song titles, artist names).
The process may include generating one or more class models associated with respective classes.
For instance, in response to receiving the voice query, the server may generate the class models that collectively identify a set of terms based on the context associated with either the audio data or the searcher.
The class models may also collectively identify a respective class to which each respective term in the set of terms fits. At least some of these terms go to different classes.
For example, as depicted in FIG. 1, the class models are each associated with different classes (e.g., #SONG and #CONTACT classes), and identify a set of terms associated with each respective class.
The process may include accessing a language model. For instance, the language model processor of the server may access the processed language model that includes a residual unigram symbol representing a set of terms that are unlikely to occur within language associated with the language model.
The processed language model may use the language model processor by training the initial language model using training data that includes a residual unigram or class symbol that replaces, e.g., unknown terms in a language or terms that follow some other criteria.
In other implementations, the language model processor may process the initial language model post-training to incorporate the terms included within the residual unigram model to generate the processed language model.
The process may include processing the language model for each respective class.
For instance, the language model processor of the server may process the language model to generate the language model.
The processing may include inserting a respective class symbol associated with a respective class at each instance of the residual unigram that occurs within the language model, to generate the language model.
In the example depicted in FIG. 1, the language model processor inserts the symbols “#SONG” and “#CONTACT,” associated with the SONG and CONTACT classes, respectively, into each instance of the “#UNK” symbol.
The insertion may work with such that each class model into each instance of a residual unigram.
The process may include generating a transcription.
For instance, the transcription module of the server may generate the transcription of the utterance of the searcher using the modified language model, which is then transmitted for output in response to the received voice query.
The transcription module may access the class-based language models that correspond to the classes associated with the class models to which the terms included within the class models are assigned (e.g., SONG and CONTACT classes).
The transcription module then determines a respective probability that a term within the respective class occurs within a candidate language sequence at a position in the candidate language sequence that corresponds to a position of the respective class symbol for each respective class symbol inserted into the modified language model.
This determination uses the probabilities indicated by a particular one of the class-based language models that correspond to the respective class indicated by the respective class symbol associated with the class models. For example, for the processed query “PLAY THE #SONG SENT FROM #CONTACT,” at each instance of a respective class symbol, the transcription module may identify terms to be placed in the instance of the respective class model based on the terms collectively identified by the class models, and then identify the corresponding probabilities associated with the terms occurring within a candidate recognition sequence specified by the class-based language models.
The transcription module may then generate the transcription of the utterance of the searcher using determined probabilities with the class-based language models.
Alternatively, in other instances, the transcription module may initially generate the interpolated language model that includes the determined probabilities within the class-based language models, and then generate the transcription using the interpolated language model.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: