Why Key-Value Pairs in this document processing system?
Writing this post reminded me of a 2007 post I wrote about local search and structured data where Key-value pairs were an important aspect of that 2007 patent. The post was:
Structured Information in Google’s Local Search.
t struck me as interesting to see Google writing about inserting key-value pairs in a document processing system like the one here, with a machine Learning approach at its heart, getting into technical SEO.
Related Content:
- Technical SEO Agency
- Ecommerce SEO Agency
- Shopify SEO Services
- Franchise SEO Agency
- Enterprise SEO Services
The usages of key-value Ppairs are still important now after 15 years.
Document Processing At Google
Understanding document processing (e.g., invoices, pay stubs, sales receipts, and the like) is a crucial business need. A large fraction (e.g., 90% or more) of enterprise data gets stored and represented in unstructured documents. Extracting structured data from records can be expensive, time-consuming, and error-prone.
This patent describes a document processing parsing system and a method implemented as computer programs on computers in locations that convert unstructured documents to structured key-value pairs.
The parsing system gets configured to document processing to identify “key” textual data and corresponding “value” textual data in the paper. The key defines a label that characterizes (i.e., is descriptive of) a corresponding value.
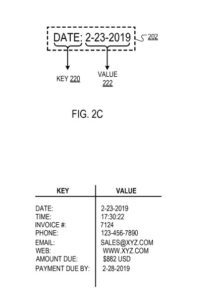
For example, the key “Date” may correspond to the value “2-23-2019”.
There is a method performed by data processing apparatus, which provides an image of a document to a detection model, wherein: the detection model gets configured to process the image by values of a plurality of detection model parameters to generate an output that defines bounding boxes generated for the idea.
Each bounding box generated for the image gets predicted to enclose a key-value pair comprising critical textual data and value textual data, wherein the necessary textual data defines a label that characterizes the textual value data.
Each of the bounding boxes generated for the image: identifies textual information enclosed by the bounding box using an optical character recognition technique; determining whether the textual data held by the bounding box defines a key-value pair; and in response to determining that the textual data enclosed by the bounding box represents a key-value pair, providing the key-value couple for use in characterizing the document.
The detection model is a neural network model.
The neural network model comprises a convolutional neural network.
The neural network model gets trained on a set of training examples. Each training example comprises a training input and a target output; the training input includes a training image of a training document. The target output contains data defining bounding boxes in the training image enclosing a respective key-value pair.
The document is an invoice.

Providing an image of a document to a detection model comprises: identifying a particular class of the paper; and providing the idea of the document to a detection model that gets trained to process copies of the specific type.
- Determining whether the textual data enclosed by the bounding box defines a key-value pair comprises:
- Deciding that the textual information possessed by the bounding box includes a key from a predetermined set of valid keys;
- Finding a type of a part of textual data held by the bounding box that does not have the key; identifying a location of suitable varieties for values corresponding to the key
- Choosing that the style of the part of the textual data enclosed by the bounding box that does not include the key gets included in the set of valid types for values corresponding to the key.
- Learning that a set of valid types for values corresponding to the key comprises: mapping the key to the collection of suitable kinds for values corresponding to the key using a predetermined mapping.
The set of valid keys and the mapping from keys to corresponding locations of suitable types for values corresponding to the keys get provided by a user.
The bounding boxes have a rectangular shape.
The method further comprises: receiving the document from a user; and converting the paper to an image, wherein the painting depicts the document.
A method performed by the document processing system, the method comprising:
- Providing an image of a document to a detection model configured to process the image to identify in the image bounding boxes predicted to enclose a key-value pair comprising critical textual data and value textual data, wherein the key defines a label that characterizes a value corresponding to the key; for each of the bounding boxes generated for the image,
- Identifying textual data enclosed by the bounding box using an optical character recognition technique and determining whether the textual information held by the bounding box defines a key-value pair
- Outputting the key-value team for use in characterizing the document.
The detection model is a machine learning model with parameters that can be trained on a training data set.
The machine learning model comprises a neural network model, particularly a convolutional neural network.
The machine learning model gets trained on a set of training examples, and each training example has a training input and a target output.
The training input comprises a training image of a training document. The target output includes data-defining bounding boxes in the training image that each encloses a respective key-value pair.
The document is an invoice.
Providing an image of a document to a detection model comprises: identifying a particular class of the paper; and providing the idea of the document to a detection model that gets trained to process documents of the specific type.
Is It a Key-Value Pair?
Determining whether the textual data enclosed by the bounding box defines a key-value pair means:
- Deciding that the textual information possessed by the bounding box includes a key from a predetermined set of valid keys
- Finding a type of a part of textual data held by the bounding box that does not have the key
- Noting a location of suitable varieties for values corresponding to the key
- Picking that the style of the part of the textual data enclosed by the bounding box that does not include the key gets included in the set of valid types for values corresponding to the key.
Identifying a set of valid types for values corresponding to the key comprises: mapping the key to the collection of proper kinds for values corresponding to the key using a predetermined mapping.
The set of valid keys and the mapping from keys to corresponding locations of suitable types for values corresponding to the keys get provided by a user.
The bounding boxes have a rectangular shape.
The method further comprises: receiving the document from a user; and converting the paper to an image, wherein the painting depicts the document.
According to another aspect, there is a system comprising: computers; and storage devices coupled to computers, wherein the storage devices store instructions that, when executed by computers, cause computers to perform operations comprising the operations of the earlier described method.
Advantages Of This Document Processing Approach
The system described in this specification can get used to convert large numbers of unstructured documents into structured key-value pairs. Thus, the system obviates the need for extracting structured data from unstructured documents, which can be expensive, time-consuming, and error-prone.
The system described in this specification can identify key-value pairs in documents with a high level of accuracy (e.g., for some types of documents, with greater than 99% accuracy). Thus, the system may be suitable for deployment in applications (e.g., processing financial documents) that need a high level of accuracy.
The system described in this specification can generalize better than some conventional systems, i.e., it has improved generalization capabilities compared to some traditional methods.
In particular, by leveraging a machine-learned detection model trained to recognize visual signals that distinguish key-value pairs in documents, the system can identify key-value pairs of the specific style, structure, or content of the papers.
The Identifying Key-Value Pairs in Document Processing Patent
Identifying key-value pairs in documents
Inventors: Yang Xu, Jiang Wang, and Shengyang Dai
Assignee: Google LLC
US Patent: 11,288,719
Granted: March 29, 2022
Filed: February 27, 2020
Abstract
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for converting unstructured documents to structured key-value pairs.
In one aspect, a method comprises: providing an image of a document to a detection model, wherein: the detection model gets configured to process the image to generate an output that defines bounding boxes generated for the image; and each bounding box generated for the image gets predicted to enclose a key-value pair comprising key textual data and value textual data, wherein the key textual data defines a label that characterizes the value textual data, and for each of the bounding boxes generated for the image: identifying textual data enclosed by the bounding box using an optical character recognition technique, and determining whether the textual data enclosed by the bounding box defines a key-value pair.
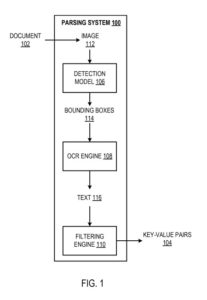
An Example Parsing System
The parsing system is an example of a method implemented as computer programs on computers in locations where the systems, components, and techniques described below get implemented.
The parsing system gets configured to process a document (e.g., an invoice, pay stub, or sale receipt) to identify key-value pairs in the paper. A “key-value pair” refers to a key and a corresponding value, generally textual data. “Textual data” should get understood to refer to at least: alphabetical characters, numbers, and special symbols. As described earlier, a key defines a label that characterizes a corresponding value.
The system may receive the document in a variety of ways.
For example, the system can receive the paper as an upload from a remote system user over a data communication network (e.g., using an application programming interface (API) made available by the system). The document can get represented in any appropriate unstructured data format, for example, as a Portable Document Format (PDF) document or as an image document (e.g., a Portable Network Graphics (PNG) or Joint Photographic Experts Group (JPEG) document).
Identify Key-Value Pairs In Document Processing
The system uses a detection model, an optical character recognition (OCR) engine, and a filtering engine to identify key-value pairs in document processing.
The detection model gets configured to process an image of the document to generate an output that defines bounding boxes in the picture. Each gets predicted to enclose textual data representing a respective key-value pair. That is, each bounding box gets expected to have textual information that defines:
(i) a key, and
(ii) a value corresponding to the key. For example, a bounding box may enclose the textual data “Name: John Smith,” which defines the key “Name” and the corresponding value “John Smith.” The detection model may be configured to generate bounding boxes that enclose a single key-value pair (i.e., rather than many key-value couples).
The image of the document is an ordered collection of numerical values that represent the paper’s visual appearance. The image may be a black-and-white image of the document. In this example, the picture may get described as a two-dimensional array of numerical intensity values. As another example, the image may be a color image of the document. In this example, the picture may get represented as a multi-channel image. Each channel corresponds to a respective color (e.g., red, green, or blue) and gets defined as a two-dimensional array of numerical intensity values.
The bounding boxes may be rectangular bounding boxes. A rectangular bounding box may get represented by the coordinates of a particular corner of the bounding box and the corresponding width and height of the bounding container. More generally, other bounding box shapes and other ways of representing the bounding boxes are possible.
While the detection model may recognize and use any frames or borders present in the document as visual signals, the bounding boxes are not constrained to align (i.e., be coincident) with any existing structures of boundaries current in the paper. Moreover, the system may generate the bounding boxes without displaying the bounding boxes in the image of the document.
That is, the system may generate data defining the bounding packages without giving a visual sign of the position of the bounding boxes to a user of the system.
The detection model is generally a machine learning model, that is, a model having a set of parameters that can get trained on a set of training data. The training data includes many training examples, each of which includes:
(i) a training image that depicts a training document, and
(ii) a target output that defines bounding boxes enclose a respective key-value pair in the training image.
The training data may get generated by manual annotation, that is, by a person identifying bounding boxes around key-value pairs in the training document (e.g., using an appropriate annotation software).
Training the detection model using machine learning techniques on a set of training data enables it to recognize visual signals that will allow it to identify key-value pairs in documents. For example, the detection model may be trained to recognize local signals (e.g., text styles and the relative spatial positions of words) and global signals (e.g., the presence of borders in the document) to identify key-value pairs.
The visual cues that enable the detection model to remember key-value teams in records generally do not include signals representing the explicit meaning of the words in the document.
Visual Signals That Distinguish Key-Value Pairs
Training the detection model to recognize visual signals that distinguish key-value pairs in documents enables the detection model to “generalize” beyond the training data used to prepare the detection model. The trained detection model might process an image depicting a document to generate bounding boxes enclosing key-value pairs in the paper even if the copy was not included in the training data used to train the detection model.
In one example, the detection model may be a neural network object detection model (e.g., including convolutional neural networks), where the “objects” correspond to key-value pairs in the document. The trainable parameters of the neural network model include the weights of the neural network model, for example, weights that define convolutional filters in the neural network model.
The neural network model may get trained on the training data set using an appropriate machine learning training procedure, for example, stochastic gradient descent. In particular, at each training iteration, the neural network model may process training images from a “batch” (i.e., a set) of training examples to generate bounding boxes predicted to enclose respective key-value pairs in the training images. The system may test an aim function that characterizes a measure of similarity between the bounding boxes generated by the neural network model and the bounding boxes specified by the corresponding target outputs of the training examples.
The measure of similarity between two bounding boxes may be, for example, a sum of squared distances between the respective vertices of the bounding boxes. The system can determine gradients of the aim function won the neural network parameter values (e.g., using backpropagation) and after that use the slopes to adjust the current neural network parameter values.
In particular, the system can use the parameter update rule from any appropriate gradient descent optimization algorithm (e.g., Adam or RMSprop) to adjust the current neural network parameter values using the gradients. The system trains the neural network model until a training termination criterion is met (e.g., until a predetermined number of training iterations have been performed or a change in the value of the object aim function between training iterations falls below a predetermined threshold).
Before using the detection model, the system may identify a “class” of the document (e.g., invoice, pay stub, or sales receipt). A user of the system may identify the class of the record upon providing the document to the system. The method may use a classification neural network to classify the class of the paper. The system may use OCR techniques to identify the text in the document and, after that, place the document’s style based on the text in the document. In a particular example, in response to determining the phrase “Net Pay,” the system may identify the paper class as a “pay stub.”
In another particular example, in response to identifying the phrase “Sales tax,” the system may identify the class of the document as “invoice.” After identifying the particular class of the record, the system may use a detection model that gets trained to process copies of the specific class. The method may use a detection model that got trained on training data that included only documents of the same particular class as the document.
Using a detection model that gets trained to process documents of the same class as the document may enhance the performance of the detection model (e.g., by enabling the detection model to generate bounding boxes around key-value pairs with greater accuracy).
For each bounding box, the system processes the part of the image enclosed by the bounding box using the OCR engine to identify the textual data (i.e., the text) held by the bounding box. In particular, the OCR engine identifies the text enclosed by a bounding box by identifying each alphabetical, numerical, or unique character enclosed by the bounding box. The OCR engine can use any appropriate technique to identify the text surrounded by a bounding box.
The filtering engine determines whether the text enclosed by a bounding box represents a key-value pair. The filtering engine can decide if the text surrounding the bounding box represents a key-value pair appropriately. For example, the filtering engine may determine whether the text enclosed by the bounding box includes a valid key from a predetermined set of right keys for a given bounding box. For example, the collection of valid keys may consist of: “Date,” “Time,” “Invoice #,” “Amount Due,” and the like.
In comparing different portions of text to determine whether the text enclosed by the bounding box includes a valid key, the filtering engine may determine that two pieces of text are “matching” even if they are not identical. For example, the filtering engine may determine that two portions of the reader are matching even if they include different capitalization or punctuation (e.g., the filtering system may determine that “Date,” “Date:” “date,” and “date:” are all matching).
In response to determining that the text enclosed by the bounding box does not include a valid key from the right keys, the filtering engine determines that the text surrounded by the bounding box does not represent a key-value pair.
In response to determining that the text enclosed by the bounding box includes a valid key, the filtering engine identifies a “type” (e.g., alphabetical, numerical, temporal) of the part of text enclosed by the bounding box not identified as the key (i.e., the “non-key” text). For example, for a bounding box that has the text: “Date: 2-23-2019”, where the filtering engine identifies “Date:” as the key (as described earlier), the filtering engine may identify the type of the non-key text “2-23-2019” as being “temporal.”
Besides identifying the type of the non-key text, the filtering engine identifies a set of valid types for values corresponding to the key. In particular, the filtering engine may map the key to a group of helpful data types for values corresponding to the key by a predetermined mapping. For example, the filtering engine may map the key “Name” to the corresponding value data type “alphabetical,” indicating that the value corresponding to the key should have an alphabetical data type (e.g., “John Smith”).
As another example, the filtering engine may map the key “Date” to the corresponding value data type “temporal,” indicating that the value corresponding to the key should have a temporal data type (e.g., “2-23-2019” or “17:30:22”).
The filtering engine determines whether the type of the non-key text gets included in the set of valid kinds for values corresponding to the key. In response to determining that the style of the non-key text gets included in the collection of suitable types for values corresponding to the legend, the filtering engine determines that the text enclosed by the bounding box represents a key-value pair. In particular, the filtering engine identifies the non-key text as the value corresponding to the key. Otherwise, the filtering engine determines that the text enclosed by the bounding box does not represent a key-value pair.
The set of valid keys and the mapping from right keys to locations of helpful data types for values corresponding to the valid keys may get provided by a system user (e.g., through an API made available by the system).
After identifying key-value pairs from the text enclosed by respective bounding boxes using the filtering engine, the system outputs the identified key-value pairs. For example, the system can provide the key-value teams to a remote user of the system over a data communication network (e.g., using an API made available by the system). As another example, the system can store data defining the identified key-value pairs in a database (or other data structure) accessible to the system’s user.
In some cases, a system user may request that the system identify the value corresponding to the particular key in the document (e.g., “Invoice #”). In these cases, rather than identifying and providing every key-value pair in the record, the system may process the text placed in respective bounding boxes until the requested key-value team recognizes and executes the ordered key-value pair.
As described above, the detection model can get trained to generate bounding boxes that each enclose a respective key-value pair. Or, rather than using a single detection model, the system may include:
(i) a “key detection model” that gets trained to generate bounding boxes that enclose respective keys, and
(ii) a “value detection model” that gets trained to generate bounding boxes that enclose respective values.
The system can identify key-value pairs from the key bounding boxes and the value bounding boxes appropriately. For example, for each team of bounding boxes that includes a key bounding box and a value bounding box, the system can generate a “match score” based on:
(i) the spatial proximity of the bounding boxes,
(ii) whether the key bounding box encloses a valid key, and
(iii) whether the type of the value enclosed by the value bounding box gets included in a set of valid types for values corresponding to the key.
The system may identify the key enclosed by a key bounding box and the value surrounded by a value bounding box as a key-value pair if the match score between the key bounding box and the value bounding box exceeds a threshold.
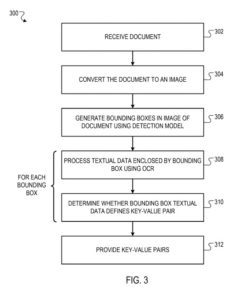
An Example Of An Invoice Document
A user of the document processing system may provide the invoice (e.g., as a scanned image or a PDF file) to the parsing system.
Bounding boxes are generated by the detection model of the parsing system. Each bounding box is predicted to enclose textual data that defines a key-value pair. The detection model does not generate a bounding box that has text (i.e., “Thank you for your business!”) since this text does not represent a key-value pair.
The parsing system uses OCR techniques to identify the text inside each bounding box and thereafter identifies good key-value pairs enclosed by the bounding boxes.
The key (i.e., “Date:”) and the value(i.e., “2-23-2019”) enclosed by the bounding box.
Key-Value Pairs And Document Processing
A parsing system programmed by this specification can perform document processing.
The system receives a document as an upload from a remote system user over a data communication network (e.g., using an API made available by the system). The document can be represented in any appropriate unstructured data format, such as a PDF document or an image document (e.g., a PNG or JPEG document).
The system converts the document to an image, that is, an ordered collection of numerical values that represents the visual appearance of the paper. For example, the image may be a black-and-white image of the document that gets described as a two-dimensional array of numerical intensity values.
By a set of detection model parameters to generate an output that defines bounding boxes in the image of the document. Each bounding box gets predicted to enclose a key-value pair including critical textual data and value textual data, where the key defines a label that characterizes the value.
The detection model may be an object detection model that includes convolutional neural networks.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: