The First Claims of Determining Dialog States For Language Models
Chances are that you have seen human-to-computer dialog patents from Google. I have written about some in the past. Here are two that provide a lot of details about such dialog:
In addition to looking carefully at patents involving human to computer dialog, it is worth spending time with Natural Language Processing, and communications between human beings and computers. I have also written about a few of those. Here are a couple of them:
This Google Determining Dialog States For Language Models patent has been updated twice now, with the latest version being granted earlier this week. The lastest first claim is a little longer and has some new words added to it.
Related Content:
- Technical SEO Agency
- Ecommerce SEO Agency
- Shopify SEO Services
- Franchise SEO Agency
- Enterprise SEO Services
Ideally, these patents have to start with a deep look at the language of the claims.
The Second version of Determining dialog states for language models, filed on 18, 2018, and granted February 4, 2020, starts off with the following claim:
- What is claimed is:
- 1. A computer-implemented method, comprising:
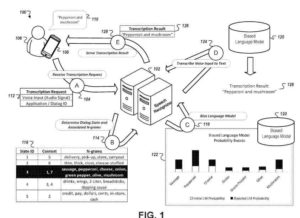
- Receiving, by a computing device, audio data for a voice input to the computing device, wherein the voice input corresponds to an unknown stage of a multi-stage voice dialog between the computing device and a user of the computing device
- Determining an initial prediction for the unknown stage of the multi-stage voice dialog
Providing, by the computing device and to a voice dialog system,- (i) the audio data for the voice input to the computing device and
- (ii) an indication of the initial prediction for the unknown stage of the multi-stage voice dialog
- Receiving, by the computing device and from the voice dialog system, a transcription of the voice input, wherein the transcription was generated by processing the audio data with a model that was biased according to parameters that correspond to a refined prediction for the unknown stage of the multi-stage voice dialog, wherein the voice dialog system is configured to determine the refined prediction for the unknown stage of the multi-stage voice dialog based on (i) the initial prediction for the unknown stage of the multi-stage voice dialog and
- (ii) additional information that describes a context of the voice input, and wherein the additional information that describes the context of the voice input is independent of content of
- the voice input; and presenting the transcription of the voice input with the computing device.
The first version of this continuation patent, Determining dialog states for language models, filed March 16, 2016, and granted May 22, 2018, begins with this claim:
- What is claimed is:
- 1. A computer-implemented method, comprising:
- Receiving, at a computing system, audio data that indicates a first voice input that was provided to a computing device
- Determining that the first voice input is part of a voice dialog that includes a plurality of pre-defined dialog states arranged to receive a series of voice inputs related to a particular task, wherein each dialog state is mapped to: (i) a set of display data characterizing content that is designated for display when voice inputs for the dialog state are received, and
(ii) a set of n-grams - Receiving, at the computing system, first display data that characterizes content that was displayed on a screen of the computing device when the first voice input was provided to the computing device; selecting, by the computing system, a particular dialog state of the plurality of pre-defined dialog states that corresponds to the first voice input, including determining a match between the first display data and the corresponding set of display data that is mapped to the particular dialog state; biasing a language model by adjusting probability scores that the language model indicates for n-grams in the corresponding set of n-grams that are mapped to the particular dialog state; and transcribing the voice input using the biased language model.
The most recent first claim in the latest version of this patent, Determining dialog states for language models, was filed January 2, 2020, and granted on March 1, 2022. It tells us:
- What is claimed is:
- 1. A computer-implemented method, comprising:
- Obtaining transcriptions of voice inputs from a training set of voice inputs, wherein each voice input in the training set of voice inputs is directed to one of a plurality of stages of a multi-stage voice activity
- Obtaining display data associated with each voice input from the training set of voice inputs that characterizes content that is designated for display when the associated voice input is received; generating a plurality of groups of transcriptions, wherein each group of transcriptions includes a different subset of the transcriptions of voice inputs from the training set of voice inputs
- Assigning each group of transcriptions to a different dialog state of a dialog-state model that includes a plurality of dialog states, wherein each dialog state of the plurality of dialog states: corresponds to a different stage of the multi-stage voice activity; and is mapped to a respective set of the display data characterizing content that is designated for display when voice inputs from the training set of voice inputs that are associated with the group of transcriptions assigned to the dialog state are received; for each group of transcriptions, determining a representative set of n-grams for the group, and associating the representative set of n-grams for the group with the corresponding dialog state of the dialog-state model to which the group is assigned, wherein the representative set of n-grams determined for the group of transcriptions comprise n-grams-satisfying a threshold number of occurrences in the group of transcriptions assigned to the dialog state of the dialog-state model
- Receiving a subsequent voice input and first display data characterizing content that was displayed on a screen when the subsequent voice input was received, the subsequent voice input directed toward a particular stage of the multi-stage voice activity
Determining a match between the first display data and the respective set of display data mapped to the dialog state in the dialog-state model that corresponds to the particular stage of the multi-voice activity - Processing, with a speech recognizer, the subsequent voice input, and the first display data, including biasing the speech recognizer using the representative set of n-grams associated with the dialog state in the dialog-state model that corresponds to the particular stage of the multi-voice activity
\
Comparing the Claims of the Determining Dialog States for Language Models
These are some of the differences that I am seeing with the different versions of the patent:
1. All three versions tell us that they are about”voice inputs,” which act as part of a training set.
So unlike the previous patents about Dialog states between humans and computers, which focused on the content of the dialog, this patent primarily looks at verbal language and actual voice inputs.
2. The second and third versions of the patent describe breaking transcripts of the voice inputs into ngrams, which can be helpful n calculating statistics about occurrences of the voice inputs used.
3. The claim of the newest and third version of the Patent etermining dialog states for language models mentions the use of a speed recognizer.
- What is claimed is:
- 1. A computer-implemented method, comprising: receiving, at a computing system, audio data that indicates a first voice input that was provided to a computing device; determining that the first voice input is part of a voice dialog that includes a plurality of pre-defined dialog states arranged to receive a series of voice inputs related to a particular task, wherein each dialog state is mapped to:
- (i) a set of display data characterizing content that is designated for display when voice inputs for the dialog state are received, and
- (ii) a set of n-grams; receiving, at the computing system, first display data that characterizes content that was displayed on a screen of the computing device when the first voice input was provided to the computing device
- Selecting, by the computing system, a particular dialog state of the plurality of pre-defined dialog states that corresponds to the first voice input, including determining a match between the first display data and the corresponding set of display data that is mapped to the particular dialog state
- Biasing a language model by adjusting probability scores that the language model indicates for n-grams in the corresponding set of n-grams that are mapped to the particular dialog state
- Transcribing the voice input using the biased language model.
Determining dialog states for language models
Inventors: Petar Aleksic, and Pedro J. Moreno Mengibar
Assignee: Google LLC
U.S. Patent: 11,264,028
Granted: March 1, 2022
Filed: January 2, 2020
Abstract
Systems, methods, devices, and other techniques are described herein for determining dialog states that correspond to voice inputs and for biasing a language model based on the determined dialog states. In some implementations, a method includes receiving, at a computing system, audio data that indicates a voice input and determining a particular dialog state, from among a plurality of dialog states, which corresponds to the voice input. A set of n-grams can be identified that are associated with the particular dialog state that corresponds to the voice input. In response to identifying the set of n-grams that are associated with the particular dialog state that corresponds to the voice input, a language model can be biased by adjusting probability scores that the language model indicates for n-grams in the set of n-grams. The voice input can be transcribed using the adjusted language model.
Search News Straight To Your Inbox
*Required
About Bill Slawski
With more than 26 years of SEO experience and a Juris Doctor Degree, Bill Slawski is the foremost expert on Google’s patents as related to SEO. Patent Exploration is one of the quickest and most detailed ways to find new information about SEO. Bill is the Editor of SEO by the Sea, a prominent search engine optimization blog, where he is the author of over 1,300 posts. Bill’s experience includes Fortune 500 brands and some of the largest websites in the world. Bill is a contributing author for Moz, Search Engine Land, and Search Engine Journal. In 2014-2021, he spoke at industry-leading international conferences about topics including search engine algorithms, universal and blended search, personalization in search, search and social, and duplicate content problems, structured data, and schemaJoin thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: