Table of Contents
Something that’s important for SEOs to consider is that in order to understand your content, Google needs to translate it into a numeric value. This is the beset way that search engines can efficiently understand the contents of the web at scale. This conversion is done through what’s called an “embedding model”.
What’s extremely powerful is that once you convert two sets of text into numeric values, you can then measure the “distance” between them (cosine similarity). This is a mathematical representation of how close to each text value is to one another. The closer they are, the more similar the content is and the more relevant it’s perceived to be. In fact, search engines like Google directly use Similarity to understand if a given page is a close enough match for a given query.
At Go Fish Digital, we wanted to better showcase how Google search and vector embeddings worth together. To demonstrate this, we created a simple Python script that allows you to use BERT in order to calculate how similar a given piece of text is for a target keyword. By running this script you can see there’s a direct Similarity calculation between a given piece of text on the site and the target query.
Here’s how you use it:
Download The Python Script Below
In a text editor, copy & paste the below Python script somewhere on your computer and name it “BERT.py”
————————-
import torch
from transformers import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity
def get_embedding(text, model, tokenizer):
inputs = tokenizer(text, return_tensors=’pt’)
outputs = model(**inputs)
return outputs.last_hidden_state.mean(dim=1).detach().numpy()
def main():
sentence = input(“Sentence: “)
keyword = input(“Keyword: “)
tokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)
model = BertModel.from_pretrained(‘bert-base-uncased’)
sentence_embedding = get_embedding(sentence, model, tokenizer)
keyword_embedding = get_embedding(keyword, model, tokenizer)
# Calculate cosine similarity
similarity_score = cosine_similarity(sentence_embedding, keyword_embedding)[0][0]
# Truncate embeddings for display
sentence_embedding_truncated = sentence_embedding[0][:10]
keyword_embedding_truncated = keyword_embedding[0][:10]
print(f”Sentence: {sentence}”)
print(f”Embedding: {sentence_embedding_truncated.tolist()} …”)
print(f”Keyword: {keyword}”)
print(f”Embedding: {keyword_embedding_truncated.tolist()} …”)
print(f”Similarity Score: {similarity_score:.4f}”)
if __name__ == “__main__”:
main()
Install Transformers In Your Terminal
Next, you’ll want to install the Transformers library from Hugging Face. Open up your Terminal and run the following command:
pip install transformers torch
Execute BERT.py
Next you’ll want to execute the actual Python script. In your Terminal, you’re going to want to navigate to the folder on your machine where you have the file saved. To do this, you can right-click your BERT.py file and then hold down the “Option” key. You’ll see an option to “Copy as a pathname”. You can use the “cd” command to change directories to that pathname.
For me, I used this command to access my downloads folder:
cd /Users/username/Downloads/
Once there, you’ll simply run the python script by using the following command:
python BERT.py
You’ll then be prompted to fill out both the content you want to analyze and the keyword you want to compare is against. Type a sentence you’ like to analyze and then hit enter. Next, enter in the keyword you’re targeting.
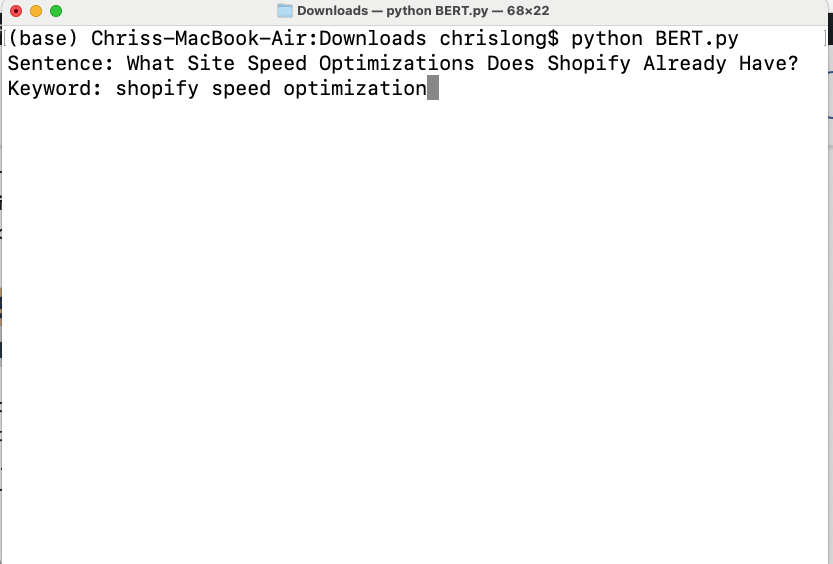
Generating Embeddings From Text
The first thing the script does is generate a 768 point vector array, or an embedding, for both the sentence and the target keyword. We truncated this to just 10 vectors for visual purposes. When we say that google creates an embedding, we mean they generate one of these 768 point vector for a piece of content on your site. This may be entities, paragraphs, headings, or other chunks of text on your page. In fact, Google can use this same process to convert an image into a 768 point vector array. Once they have text and images converted into numbers, they can start to process them algorithmically. One way is to measure how far apart two vectors are.
Analyze Your Content Similarity Score
Next, the Python script will take thw generated embeddings for the sentence and keyword and output a “Similarity Score”. This will be a score from 0 to 1 on how relevant the text is to the query that you entered.
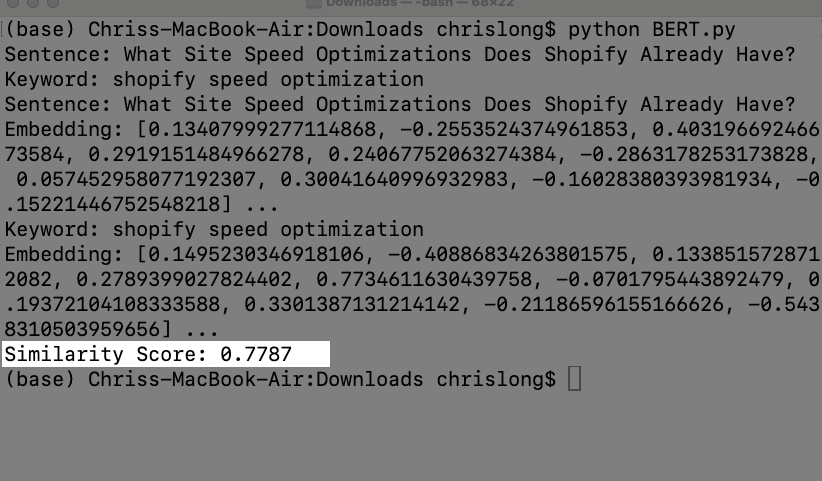
Now this is an extremely simplified way of understanding how relevant your content is to a given query. However it is useful to understand the technical process Google uses to process, understand, and score your content. You can also use this type of approach as it lets you put a numeric value to your content in terms of how targeted it actually is for the query you want to analyze.
Go Fish Digital’s Similarity Tools
At Go Fish Digital, we’ve actually build some custom Chrome extensions that are able to perform this type of analysis for every section of content on an entire page. The tool will ask for a input query, scrape each section of content on a page, calculate Similarity and then score all analyzed sections. You can see the processed visualized below:
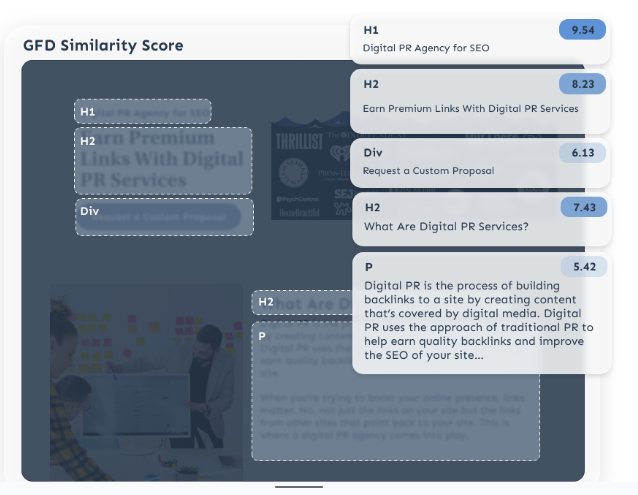
This means, that for an entire page, you can analyze your content section by section to see what’s scoring high in terms of Similarity and what isn’t. You can also run this analysis on competitor pages to see where potential gaps might be. We’re currently running demos on how this tool works for individual sites so don’t hesitate to reach out if you want to learn more.
Search News Straight To Your Inbox
*Required
About Chris Long
Chris Long is the VP of Marketing at Go Fish Digital. With 10+ years of SEO experience, Chris works unique problems and advanced search situations to help clients improve organic traffic through a deep understanding of Google's algorithm and web technology. Chris has advised on the search strategies for clients such as GEICO, Adobe & The New York Times. He is a contributor for Moz, Search Engine Land, and Search Engine Journal. He is also a speaker at industry conferences such as MozCon, SMX East, BrightonSEO and more.Join thousands of marketers to get the best search news in under 5 minutes. Get resources, tips and more with The Splash newsletter: